ChatGPT and Cheat Detection in CS1 Using a Program Autograding System
Frank Vahid*, Lizbeth Areizaga, Ashley Pang
Dept. of Computer Science, Univ. of California, Riverside
*Also with zyBooks
Whitepaper
V1 Feb 17, 2023: Initial version.
Abstract
We summarize the ability of a program autograding system to detect programs written by ChatGPT, rather than by students, in a CS1 class using a “many small programs” approach. First, we found ChatGPT was quite good at generating correct programs from a mere copy-paste of the English programming assignment specifications. However, running ChatGPT using 10 programming assignments and acting as 20 different students, and using zyBooks’ APEX tool for academic integrity, we found: (1) ChatGPT-generated programs tend to use a programming style departing from the style taught in the textbook or by the instructor, and these “style anomalies” were automatically detected. (2) Although ChatGPT may for the same assignment generate a few different program solutions for different students, ChatGPT often generates highly-similar programs for different students, so if enough students in a class (e.g., 5 or more) use ChatGPT, their programs will likely be flagged by a similarity checker. (3) If students are required to do all programming in the autograder’s IDE, then a student using ChatGPT ends up showing very little time relative to classmates, which is automatically flagged. (4) Manually, we observed that if a student consistently uses ChatGPT to submit programs, the programming style may vary from one program to another, something normal students don’t do; automation of such style inconsistency detection is underway. In short, while there will no doubt be a nuclear arms race between AI-generated programs and the ability to automatically detect AI-generated programs, currently it is likely that students using ChatGPT in a CS1 can be detected by automated tools such as APEX.
Introduction
ChatGPT has made headlines for its ability to apply AI (artificial intelligence) to do human-like work, such as writing essays, creating emails, and writing computer programs. The tool has raised concerns among college educators who worry students will let the tool do their homework for them, such as writing essays, or in computer science courses, writing programs [Nyt23]. In fact, that general concern predates ChatGPT, because for over a decade now, students have had numerous sources of letting others do their programming, including “homework help” websites like Chegg, Coursehero, Quizlet; code repositories like GitHub; hired contractors found on sites like Reddit; friends and family; and classmates, especially via anonymous communication apps like Discord and Groupme.
Today, ChatGPT magnifies the problem, due to being even easier to access, and replying in just a few seconds.
Because the problem has existed for over a decade, we at UCR began research about 5 years ago to build tools to automatically detect cheating on programming assignments, going beyond the traditional approach of running similarity checking tools like MOSS [Sc03] on a single programming assignment. That work led to a number of publications, an ongoing NSF award (Grant No. 2111323) that is developing open-access cheat detection software, and a commercial product whose development began in late 2021 and that is currently available as a beta tool called APEX (Automated Programming EXplorer) from zyBooks, with the tool currently being beta-used by about 40 universities.
In this whitepaper, we describe early experiences of using ChatGPT to solve CS1 programming assignments, and of using APEX for detecting such use. In short, the APEX tool tends to flag students using ChatGPT as “high concern” students based on a number of metrics that were previously-developed to detect other forms of cheating.
In related research [Va23], we found that showing students the detection tool, along with a few other low-instructor-effort methods, reduced cheating rates from 32% down to 12% for one instructor, and from 56% down to 19% for another, in large CS1 classes. Akin to how nobody speeds right past a police car, our goal is to create a strong detection tool not to catch/punish students but rather to help students resist the temptation to cheat.
ChatGPT capability
On January 5, 2023, we had a student use ChatGPT to do all 7 programming assignments — henceforth called “labs” — in a particular week of a 107-student section of a previous Fall 2021 CS1 offering. That week was the seventh week of a ten week quarter, introducing vectors in C++, with the labs requiring vectors plus prior concepts like functions, loops, and branches. The course used a “many small programs” approach, assigning 5-7 labs per week (versus one large program) [Al19]. Solution sizes averaged 40 lines per lab. The student was told to simply copy-paste each English lab specification into ChatGPT preceded by “Write this in C++”, then copy-paste the generated program back to the auto-grader, without any modifications. Figure 1 shows a portion of the APEX tool’s high-level summary, showing 8 of the now 108 students (was 107) in that class’s zyBook. The students were sorted alphabetically, and the student who used ChatGPT appears in the third row, highlighted in the figure. One thing to note is that the student achieved 46 of the possible 70 points. What is especially shocking is that he achieved that score in a mere 15 minutes (in fact, the actual time was 8 minutes, but he played around a bit with one of the programs afterwards, inflating the time and runs). Writing the programs was expected to take novice students about 2 or 3 hours, and one can indeed see that other students usually took 1.5-2 hours with some taking 4 or 5 hours. Separately, we had the student try to gain the full 70 points by telling ChatGPT what tests failed, which he achieved in just another 10 minutes.
.
Figure 1: A portion of APEX’s student roster view (sorted alphabetically by student name, not shown), with the highlighted row being the student who used ChatGPT.
Next, in early February we had another student use ChatGPT to solve ALL the labs in a 15-week semester course offered by another university. The student was told to copy-paste each lab’s specification into ChatGPT, and then copy the resulting code back into the autograder, without modification. If that code did not receive 10 points, the student was told to iterate like a CS1 student might, typing in the chat things like “You missed this test case” and copy-pasting the actual and expected output from the autograder, or telling ChatGPT to include particular header files based on a compiler’s error message of missing functions. The student was told not to iterate more than twice with ChatGPT. Figure 2 provides results.
| Chapter | Title | Score no iteration | Highest score after minor iteration | Max score |
| Ch 1 | Hello World! | 10 | 10 | |
| Formatted output: No parking sign | 10 | 10 | ||
| Input and formatted output: House real estate summary | 0 | 10 | 10 | |
| Input and formatted output: Car info | 10 | 10 | ||
| Input and formatted output: Right-facing arrow | 0 | 0 | 0 | |
| Ch 2 | Convert to seconds | 10 | 10 | |
| Driving costs | 0 | 10 | 10 | |
| Expression for calories burned during workout | 10 | 10 | ||
| Ordering pizza | 10 | 10 | ||
| Caffeine levels | 0 | 10 | 10 | |
| Ch 3 | Area of triangle | 10 | 10 | |
| Simple statistics | 10 | 10 | ||
| Phone number breakdown | 10 | 10 | ||
| Using math functions | 10 | 10 | ||
| Chemistry formula | 0 | 10 | 10 | |
| Ch 4 | How many digits | 0 | 10 | 10 |
| Speeding ticket | 5 | 10 | 10 | |
| Golf scores | 10 | 10 | ||
| Largest number | 10 | 10 | ||
| Multiples | 10 | 10 | ||
| Interstate highway numbers | 0 | 9 | 9 | |
| Ch 5 | Movie ticket prices | 10 | 10 | |
| Leap year | 0 | 10 | 10 | |
| Exact change | 10 | 10 | ||
| Longest string | 10 | 10 | ||
| Phrases and subphrases | 10 | 10 | ||
| Ch 6 | Output range with increment of 5 | 10 | 10 | |
| Output inclusive/exclusive range | 1 | 10 | 10 | |
| Varied amount of input data | 10 | 10 | ||
| Mad lib- loops | 10 | 10 | ||
| Password modifier | 10 | 10 | ||
| Ch 7 | Print string in reverse | 10 | 10 | |
| Checker for integer string | 0 | 10 | 10 | |
| Count input length without end-of-sentence punctuation | 10 | 10 | ||
| Remove all non-alphabetic characters | 10 | 10 | ||
| Ch 8 | Output numbers in reverse | 0 | 10 | 10 |
| Middle item | 10 | 10 | ||
| Output values below an amount | 10 | 10 | ||
| Adjust by normalizing | 0 | Compiler error | 0 | |
| Ch 9 | Two smallest numbers | 0 | 10 | 10 |
| Elements in a range | 10 | 10 | ||
| Word frequencies | 0 | 10 | 10 | |
| Is vector sorted | 10 | 10 | ||
| Ch 10 | Track laps to miles | 8 | 10 | 10 |
| Step counter | 10 | 10 | ||
| Driving costs – functions | 10 | 10 | ||
| Max magnitude | 10 | 10 | ||
| Flip a coin | 8 | 10 | 10 | |
| Ch 11 | Swapping variables | 10 | 10 | |
| Remove all non-alphabetic characters – functions | 10 | 10 | ||
| Convert to binary – functions | 10 | 10 | ||
| Max and min numbers | 10 | 10 | ||
| Print rectangle – functions | 0 | 10 | 10 | |
| Ch 12 | Parsing dates | 0 | 0 | 0 |
| Course Grade | 0 | 10 | 10 | |
| Triangle area comparison (classes) | Compiler error | 10 | 10 | |
| Car value (classes) | 10 | 10 | ||
| Ch 13 | Vending machine | Compiler error | 10 | 10 |
| Nutritional information (classes/constructors) | 10 | 10 | ||
| Artwork label (classes/constructors) | 10 | 10 | ||
| BankAccount class | 10 | 10 | ||
| Ch 14 | Find max in list | Compiler error | 10 | 10 |
| Index of list item | Compiler error | 10 | 10 | |
| List count | Compiler error | 10 | 10 | |
| Playlist (output linked list) | Compiler error | 10 | 10 | |
| Milage tracker for runner | 10 | 10 | ||
| Ch 15 | Inventory (linked list: insert at the front of a list) | Compiler error | 10 | 10 |
| Grocery shopping list (linked list: insert at the end of a list) | Compiler error | 10 | 10 | |
| List (linked list: insert at the middle of a list) | Compiler error | 10 | 10 | |
| Average: | 7.03 | 9.25 | 9.55 |
Figure 2: Scores for ChatGPT-generated programs for an entire semester of CS1 labs.
Looking at the rightmost column, ChatGPT was able to achieve nearly perfect scores, with only a few labs not getting the full 10 points within 2 iterations, and an average score of 9.55 of 10. Even more shockingly, the student said she spent no more than 3 minutes per lab when iterating, and usually only about 1 minute due to no iterating. Thus, the student completed all 15 weeks of labs, nearly 70 labs in total, with an expected work time of about 45 hours, in just under 2 hours.
This section showed ChatGPT’s ability to quickly and correctly complete labs. Clearly, this capability will be very tempting to students.
Style anomalies
Over the past decade, we have noticed that CS1 students who let external resources write their programs — homework help websites, contractors, friends/family, GitHub repos from other schools — tend to submit programs whose coding style departs from the style taught by our book or instructors, what we call style anomalies. For example, our CS1 course in C++ uses the K&R brace style (vs. Allman or other brace styles), uses the std namespace (so students type “cout” rather than “std::cout”), declares each variable on a distinct line (rather than multiple same-type variables on the same line like int x, y;), etc. ChatGPT does not seem to use a particular style, and often departs from the class style.
In February 2023, we had a student do 10 labs from the above-mentioned 15-week course, picking 2 labs from each chapter across weeks 3 to 7. She acted like 20 different students by creating a unique ChatGPT session to represent each unique student, and copy-pasted the lab spec to ChatGPT and saving the generated program (thus generating a total of 20 * 10 = 200 programs). She then recorded APEX’s “style anomaly” score for each program. A student who is not cheating will typically have an anomaly score close to 0, typically under 5. For example, for Lab5, nearly all normal students in a 100-student class have anomaly scores of 0s; 2 had a score of 1, 7 had a score of 2, and 1 had a score of 10 — the student with 10 was detected as cheating and admitted to having an experienced friend programming for them. Those few anomalies are often typos, minor style differences that the student may have learned, or just false positives in the style anomaly detection. Students with prior programming experience sometimes have higher style anomaly scores, but professors quickly learn who those students are, typically after a brief conversation asking about their program style.
Results appear in Figure 3. Most of the ChatGPT “students” have one or more labs that yield style anomaly scores well over 5. For example, User 1’s Lab1 has a style anomaly score of 22, which is very concerning. Their Lab3 is also high at 13, and Labs 5, 6, 7, and 8 would all warrant some examination too. The rightmost column shows that all but one student has at least one lab with a style anomaly score over 5; User 4 seems to have gotten lucky, and User 5 nearly escaped detection. But most students get flagged.
| Anomaly score | |||||||||||
| Lab1 | Lab2 | Lab3 | Lab4 | Lab5 | Lab6 | Lab7 | Lab8 | Lab9 | Lab10 | Max | |
| User 1 | 22 | 4 | 13 | 3 | 9 | 7 | 8 | 7 | 3 | 2 | 22 |
| User 2 | 3 | 8 | 3 | 3 | 2 | 1 | 8 | 6 | 10 | 10 | 10 |
| User 3 | 3 | 2 | 2 | 3 | 2 | 1 | 10 | 1 | 11 | 10 | 11 |
| User 4 | 3 | 1 | 2 | 3 | 2 | 1 | 2 | 1 | 4 | 5 | 5 |
| User 5 | 0 | 7 | 2 | 3 | 0 | 1 | 2 | 1 | 4 | 5 | 7 |
| User 6 | 0 | 1 | 3 | 3 | 1 | 7 | 10 | 1 | 34 | 2 | 34 |
| User 7 | 11 | 9 | 23 | 30 | 1 | 11 | 6 | 2 | 27 | 5 | 30 |
| User 8 | 6 | 9 | 14 | 15 | 73 | 1 | 22 | 39 | 18 | 19 | 73 |
| User 9 | 0 | 1 | 3 | 3 | 0 | 1 | 10 | 1 | 9 | 3 | 10 |
| User 10 | 0 | 1 | 2 | 3 | 1 | 7 | 10 | 2 | 5 | 2 | 10 |
| User 11 | 3 | 1 | 3 | 3 | 1 | 1 | 2 | 17 | 4 | 1 | 17 |
| User 12 | 4 | 36 | 2 | 1 | 2 | 0 | 2 | 1 | 2 | 2 | 36 |
| User 13 | 3 | 1 | 2 | 3 | 0 | 1 | 3 | 1 | 11 | 5 | 11 |
| User 14 | 3 | 1 | 2 | 3 | 1 | 1 | 9 | 1 | 2 | 5 | 9 |
| User 15 | 3 | 13 | 2 | 3 | 2 | 0 | 2 | 11 | 2 | 2 | 13 |
| User 16 | 6 | 4 | 6 | 8 | 2 | 1 | 2 | 1 | 3 | 2 | 8 |
| User 17 | 3 | 1 | 1 | 1 | 2 | 0 | 8 | 1 | 2 | 8 | 8 |
| User 18 | 3 | 1 | 2 | 3 | 0 | 1 | 8 | 7 | 4 | 8 | 8 |
| User 19 | 3 | 5 | 7 | 9 | 0 | 1 | 8 | 1 | 2 | 1 | 9 |
| User 20 | 3 | 1 | 2 | 1 | 2 | 1 | 8 | 8 | 4 | 8 | 8 |
Figure 3: Style anomaly scores, as determined by APEX, for 20 simulated students across 10 labs.
Below is an example of code with style anomalies. The code uses std:: throughout (our class style uses namespace std at the top instead), and uses a while(true) loop and break statement (while(true) is never taught in that CS1, and breaks are only taught much later). The APEX tool can assign different weights to different style anomalies; the use of “while(true)” could for example be given a weight of 10, due to it being such a radical departure from the class’ style. In Figure 3, all weights were 1; further improvement of weights likely would cause ChatGPT code to stand out even more.
#include <iostream>
#include <string>
int main() {
std::string input_string;
int input_number;
while (true) {
std::cout << “”Enter a string (quit to exit): “”;
std::cin >> input_string;
if (input_string == “”quit””) {
break;
}
std::cout << “”Enter a number: “”;
std::cin >> input_number;
std::cout << “”Eating “” << input_number << “” “” << input_string << “” a day keeps you happy and healthy.”” << std::endl;
}
return 0;
}
In fact, looking back at the earlier-mentioned student who in January 2023 did all the Chapter 7 labs for our Fall 2021 course, and increasing weight from 1 to 5 on a few style anomalies that seem common in ChatGPT-generated code (array notation instead of vectors, using std::, using while(true) loops), the student appears at the top of APEX’s style anomaly list, as shown in Figure 4.
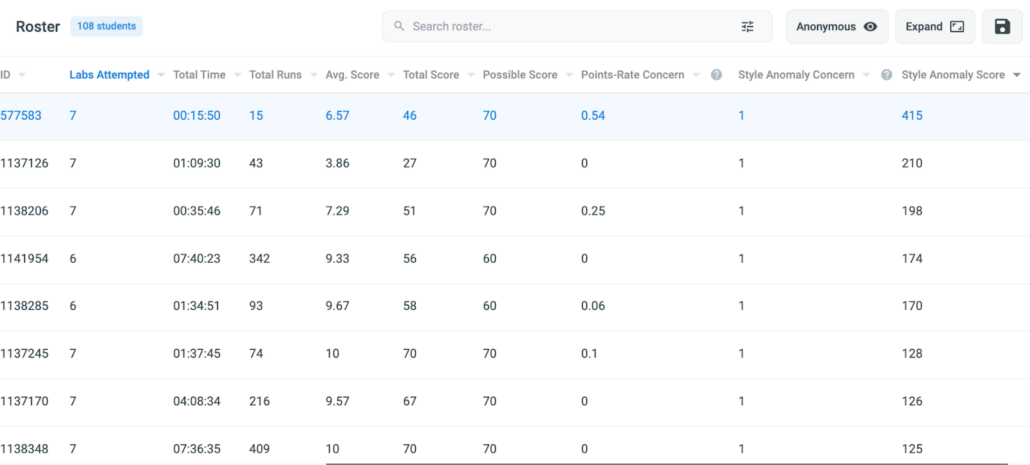
Figure 4: The student who used ChatGPT in this 108-student class appears at the top of the list when sorted by style anomaly score, with a score of 415; the next highest score is just 210. Incidentally, many of the students at the top of this list were determined to be cheating; the ChatGPT student still rises well above them in the style anomaly score.
Note: We tried having the student train ChatGPT on our class’s programming style, telling it to learn the class programming style and feeding it 3 sample programs. Then, in the same ChatGPT session window, the student would give the tool the subsequent lab specs. ChatGPT would generate the next 1-2 programs closer to the style, but would begin to forget the style and revert to using different and varying styles. Given that we typically assign 5-7 programs per week, training ChatGPT before each lab spec may become cumbersome. Of course, future ChatGPT versions may be more trainable, but currently it seems hard to automatically get ChatGPT’s style to match a class’s style. Of course, a student aware that such style checking will be used may start to alter the generated code. Some such alterations are straightforward (e.g., using namespace std and removing use of std::), but others are harder (e.g., replacing the while(true)/break structure by a loop with an expression that ends iterations). Instructors may thus wish to consider to what extent they will inform students of the details of the style anomaly tool. Instructors might also introduce particular style requirements to make it harder for external sources like ChatGPT to generate code matching the class style. And we may begin to more heavily-weigh certain styles favored by ChatGPT but anomalous to the class style.
Similarity
Initially, when we ran ChatGPT as a few different students, we were disappointed because ChatGPT created unique solutions for each student. However, as we simulated more students, we soon realized that ChatGPT does repeat solutions, with trivial variations like different variable names, such variations being ignored by most similarity checkers. Thus, if multiple students use ChatGPT in a class, it is likely that a ChatGPT user’s code will be flagged as similar to one of those other students.
For the earlier-mentioned experiment of simulating 20 students for 10 labs, we used APEX to detect highly-similar programs. APEX uses the popular MOSS algorithm [Sc03] for similarity detection, which ignores variations in whitespace, variable and function names, and some logic ordering, among other things. In our experience, for most labs, a similarity score above 90% is suggestive of copying and warrants examination by an instructor.
Figure 5 provides results. For example, User 1’s Lab1 was unique relative to classmates (0 highly-similar classmate labs), but their Lab2 and also Lab6 were each flagged as highly similar to 2 classmates, and their Lab7 was similar to 10 classmates. The rightmost column shows the max for each row, showing that every student would be flagged by the similarity checker as potentially cheating on at least 1 lab, in this class where 20 students used ChatGPT. Clearly, if fewer students use ChatGPT, such as in smaller classes or in classes with little cheating, similarity counts will be lower. But the data suggests that ChatGPT users are taking quite a risk, because ChatGPT does not guarantee uniqueness.
| Number of classmates with >= 90% similarity score | |||||||||||
| Lab1 | Lab2 | Lab3 | Lab4 | Lab5 | Lab6 | Lab7 | Lab8 | Lab9 | Lab10 | # labs with >1 similar student | |
| User 1 | 0 | 2 | 0 | 0 | 0 | 2 | 10 | 0 | 6 | 7 | 5 |
| User 2 | 10 | 0 | 0 | 1 | 4 | 15 | 10 | 0 | 1 | 0 | 6 |
| User 3 | 10 | 1 | 4 | 0 | 2 | 16 | 9 | 0 | 1 | 0 | 7 |
| User 4 | 12 | 1 | 2 | 1 | 2 | 16 | 7 | 0 | 5 | 5 | 9 |
| User 5 | 0 | 3 | 0 | 1 | 0 | 16 | 7 | 1 | 5 | 5 | 7 |
| User 6 | 0 | 3 | 5 | 4 | 6 | 1 | 9 | 1 | 5 | 7 | 9 |
| User 7 | 10 | 1 | 4 | 3 | 3 | 16 | 1 | 1 | 5 | 5 | 10 |
| User 8 | 0 | 0 | 5 | 0 | 0 | 16 | 1 | 0 | 1 | 5 | 5 |
| User 9 | 1 | 0 | 4 | 3 | 1 | 16 | 9 | 1 | 0 | 8 | 8 |
| User 10 | 1 | 1 | 0 | 2 | 5 | 1 | 9 | 1 | 0 | 7 | 8 |
| User 11 | 10 | 0 | 5 | 0 | 2 | 16 | 5 | 0 | 4 | 8 | 7 |
| User 12 | 6 | 0 | 1 | 1 | 3 | 1 | 7 | 2 | 7 | 8 | 9 |
| User 13 | 10 | 0 | 2 | 2 | 0 | 16 | 7 | 3 | 0 | 5 | 7 |
| User 14 | 10 | 0 | 0 | 0 | 2 | 16 | 10 | 4 | 7 | 5 | 7 |
| User 15 | 10 | 0 | 0 | 0 | 2 | 0 | 7 | 0 | 7 | 8 | 5 |
| User 16 | 13 | 0 | 0 | 0 | 2 | 1 | 7 | 3 | 5 | 8 | 7 |
| User 17 | 10 | 1 | 0 | 0 | 0 | 1 | 10 | 1 | 7 | 2 | 7 |
| User 18 | 10 | 2 | 1 | 4 | 0 | 16 | 10 | 1 | 7 | 2 | 9 |
| User 19 | 13 | 0 | 0 | 0 | 0 | 1 | 10 | 2 | 7 | 7 | 6 |
| User 20 | 10 | 0 | 0 | 2 | 2 | 16 | 10 | 1 | 3 | 2 | 8 |
Figure 5: Similarity results for 20 students using ChatGPT on 10 labs, showing the number of classmates to which a program has a 90% or greater similarity.
Points rate (time spent)
zyBooks optionally allows instructors to enable programming in the book using the book’s IDE. Many classes thus require all programming be done in the book, at least for certain labs. In those cases, the time spent on the lab relative to the points achieved is another potential indicator of cheating; students copying from external resources, or having experts program for them, tend to earn points at a much faster rate than their classmates. APEX includes a “Points rate concern” metric, shown in Figure 6.
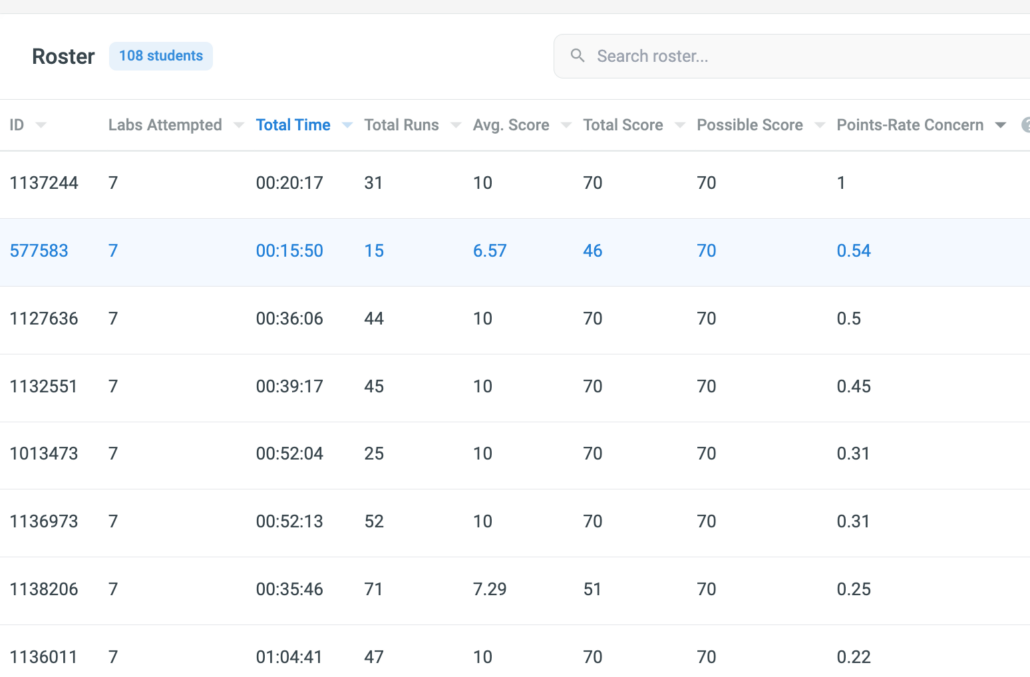
Figure 6: Points-rate concern: Our ChatGPT student appears second on the list. Again, most students near the top of this list were through detailed investigation determined to be cheating.
Even if a class has students program outside the book using an external IDE like Eclipse or Idle and then upload their program to the autograder, submission timestamps can be used to detect unusually short time between submissions of different labs that may occur if a student is using ChatGPT (assuming the student doesn’t intentionally spread their submissions, which of course some might do if they know about this detection technique). Work is planned to automate such a calculation as an alternative way to calculate the Points-Rate Concern metric when programs are written externally.
Style inconsistency
Normally, a student uses the same style across their own programs, with only minor variation. For example, no student who writes their own programs would use 3 space indents for one lab, then 5 space indents for the next lab, then no indents for the next lab, then 3 again on the next. Instead, most students use the same indent amount for each program.
ChatGPT does not seem to generate consistent code style across different programs for the same student. APEX’s single-student viewer lets an instructor easily view all of a student’s programs across all selected labs, making style inconsistencies readily apparent. Figure 7 shows a simple example from User 1 above, for Labs 1, 8, and 9. Lab1 fails to indent or use blank lines, whereas the other two programs do. Lab9 uses namespace std, whereas the other two prepend std:: to all std functions. Lab9 also lacks any comments, whereas the other two comment each segment of code. These variations from a single student writing all three programs would be highly unlikely to occur.
| Lab1 | Lab8 | Lab9 |
| #include <iostream>#include <sstream>#include <string>int main() {// Read the input phone numberlong long phone;std::cin >> phone;// Extract the area code, prefix, and line numberint area_code = phone / 10000000;int prefix = (phone / 10000) % 1000;int line_number = phone % 10000;// Use a stringstream to format the outputstd::stringstream ss;ss << “(” << area_code << “) ” << prefix << “-” << line_number;std::string output = ss.str();// Print the formatted outputstd::cout << output << std::endl;return 0;} | #include <iostream> int main() { int low, high, inclusive; std::cin >> low >> high >> inclusive; // Check if the range is valid (low is less than high) if (low >= high) { std::cout << “No output.” << std::endl; return 0; } // If the range is exclusive, increment low and decrement high if (inclusive == 0) { low++; high–; } // Print the integers within the range for (int i = low; i <= high; i++) { std::cout << i << ” “; } std::cout << std::endl; return 0;} | #include <iostream>#include <cctype> using namespace std; int main() { string input; cout << “Enter an integer: “; cin >> input; bool only_digits = true; for (char c : input) { if (!isdigit(c)) { only_digits = false; break; } } if (only_digits) { cout << “Yes” << endl; } else { cout << “No” << endl; } return 0;} |
Figure 7: ChatGPT-generated programs for User 1, showing differences in coding styles that are unlikely to occur if the same person wrote all three programs.
Work is underway to automatically detect such inconsistencies across labs, highlighting them to instructors and providing a style inconsistency score similar to the style anomaly score.
Additional techniques
Even more techniques are possible. Students copying programs found from external sources like Chegg or ChatGPT often find a program does not score sufficient points, so they then replace that program by another found program. Such code replacement is not typical when a student is writing their own programs, and can be detected automatically via calculations similar to text-difference calculations.
Students copying programs from external sources may achieve high scores on at-home programs, but then do very poorly on programs written in a proctored environment like an in-lab quiz or a midterm exam. Automated analysis can compare scores from such proctored programs to scores on at-home programs, flagging those with large differences. Furthermore, proctored programs and at-home programs can be compared based on their program style as well, flagging cases where the proctored program style varies substantially from the same student’s at-home programs.
At UCR, we are currently researching “variability-inducing requirements” that specifically reduce the likelihood of multiple students submitting the same solution to a lab. Such techniques increase the confidence that students flagged by the similarity checker, described above as happening when many students use ChatGPT, are indeed cheating versus just coincidentally submitting similar programs that the students wrote themselves. But furthermore, we have found that those techniques sometimes confuse ChatGPT. For example, one variability-inducing requirement is to format a required equation in a way that allows many translations into expressions in a program. However, we have found that such formatted equations often confuse ChatGPT, because copy-pasting into its chat box cause formatting variations that end up causing ChatGPT to implement the wrong equation. We plan to continue researching techniques that confuse AI tools, especially in ways that are predictable and thus detectable.
Some systems, like zyBook’s new “advanced zyLabs” that incorporates the Coding Rooms tool (Wiley acquired Coding Rooms in 2022), record not only every develop run or autograder submission run, but also capture every keystroke. Thus, one might conceivably determine a student’s keystroke style, leading to automated flagging of substantial variations from that style. For example, a student’s keystroke style may be consistent for Labs 1-8, but then vary substantially for Lab 9, suggesting someone else (like ChatGPT) wrote Lab 9.
To save an instructor time, APEX combines its various concern metrics into a single “Overall concern” metric. In the Chapter 7 experiment discusses earlier, our one ChatGPT student appears at the top of the list of 108 students. Note: That term about 10 students were sanctioned for cheating, so the others near the top of that list were also detected as cheating; we merely need the ChatGPT student to appear near the top of the list, but in this case they happened to be at the very top due to being detected as high on multiple concern metrics.
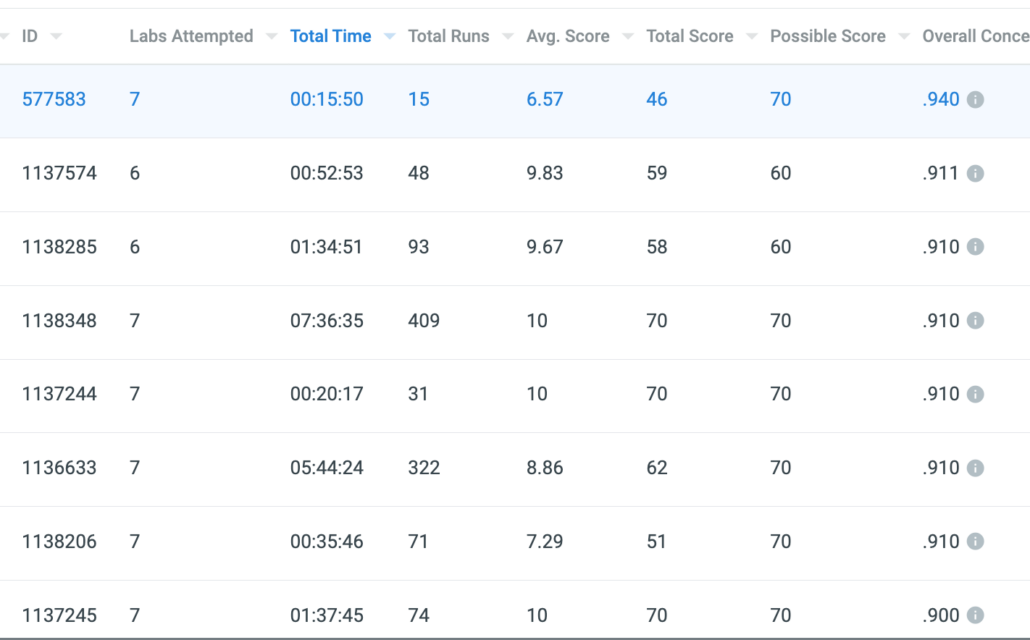
Figure 8: APEX’s overall concern metric combines the various concern metrics into a single value, by which instructors can sort students to know who to focus investigations on. The ChatGPT student appears at the top of the list of 108 students, with a score of 0.940 (highest possible is 0.999).
In this case, the ChatGPT student has high overall concern due to high style anomaly concern and high points-rate concern. Similarity concern was 0, due to this student being the only ChatGPT user in this class as the class was from Fall 2021 but the student used ChatGPT January 2023; in a contemporary class, it is likely multiple students might use ChatGPT and thus may have high similarity concern. The above overall concern does not yet consider similarity inconsistency concern, but soon will, which likely would yield an even higher overall concern score relative to classmates.
We note that in late January 2023, ChatGPT’s creator OpenAI announced a tool to detect essays written by ChatGPT [Nyp23]. It seems to mostly emphasize detecting essays. For a variety of the above labs, we fed 15 Chat-GPT-generated programs and 15 human-written solutions (half being instructor solutions, half being student-submitted solutions) to the detector. It rates all programs as “likely” or “probably” being AI-written. As such, the tool does not currently seem useful for detecting AI-written programs. This is likely due to programs being far more constrained than essays. As such, the techniques described above may be more appropriate.
Conclusion
ChatGPT magnifies the existing problem of many students using external sources to write their at-home programs, thus obtaining an inappropriately high grade for at-home programs (which, among other things, is unfair to classmates since high grades give students future advantages), and putting themselves at risk of not learning programming and then doing poorly on proctored exams, or in subsequent courses or jobs. Fortunately, automation developed over the past year to combat other external sources (Chegg, GitHub, contractors, etc.) currently works very well for detecting programs written by ChatGPT, via numerous methods. (1) zyBooks’ APEX beta tool detects the many style anomalies common in ChatGPT-generated programs. (2) Similarity checkers, like that found in APEX, will flag ChatGPT programs if used by more than a few students, because ChatGPT doesn’t generate unique programs for every student. (3) APEX can detect students earning points at an unusually fast rate compared to classmates, which works very well if all programming is done in the built-in IDE, and could also be extended to cases when an external IDE is used by detecting unusually fast completion between labs. (4) Style inconsistency can be readily observed visually using APEX’s single-student viewer that shows the programs for a single student across all selected labs, and work is underway to automatically assign a style inconsistency score as well. Additional techniques are possible too.
Several of the above methods — points-rate concern, style anomaly concern, and similarity concern — are today combined into a single Overall Concern metric for students in a class for an instructor-selected set of labs. As such, an instructor can sort students by overall concern to find students most likely to be cheating. Students using ChatGPT tend to appear high on that list, due to scoring high one or more of the individual concern metrics.
There is no doubt that as AI tools like ChatGPT continue to improve, tools like APEX will have to evolve as well — a nuclear-arms race of sorts. However, currently we seem to be ahead of the game, and students using ChatGPT are very likely to be detected by APEX. Ultimately, our goal is not to catch and punish cheating students, but instead to show students this tool — often in a fun way where we simple examine student effort as part of class activities — so that students realize cheating is likely to get caught, and instead such students decide they should just do the required at-home work appropriately. The philosophy here is that “Nobody speeds right past a cop” — if they feel the class is strongly enforcing integrity such that most students are doing the work and cheaters will be caught and punished, they are more likely to do the work, as our own research suggests as well [Va23].
Despite the threat that ChatGPT poses discussed above, we ultimately see AI tools like ChatGPT as potentially transformative in a positive way. ChatGPT can generate examples for students (and students learn from examples), can explain programs to students, and can help students debug programs — essentially serving as a low-cost, always available, non-judgemental personal tutor. And such AI tools will only get better. Like any tutor, the key to a good tutor is to give students appropriate help (and not just give students complete solutions). Providing every student with an always-available appropriate tutor is a dream of every computer science professor, and thus we look forward to a future that incorporates AI in ways to greatly benefit student learning.
Acknowledgements
This material is based upon work supported by the National Science Foundation under Grant No. 2111323.
References
[Al19] Allen, J.M., Vahid, F., Edgcomb, A., Downey, K. and Miller, K., 2019, February. An analysis of using many small programs in CS1. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education (pp. 585-591).
[Nyp23] Cheaters beware: ChatGPT maker releases AI detection tool. Feb 1, 2023, New York Post, https://nypost.com/2023/02/01/cheaters-beware-chatgpt-maker-releases-ai-detection-tool/
[Nyt23] Alarmed by A.I. Chatbots, Universities Start Revamping How They Teach, Jan 16, 2023, New York Times, https://www.nytimes.com/2023/01/16/technology/chatgpt-artificial-intelligence-universities.html
[Sc03] Schleimer S, Wilkerson, DS, Aiken A. Winnowing: local algorithms for document fingerprinting. In Proceedings of the 2003 ACM SIGMOD international conference on Management of data (pp. 76-85).
[Va23] F. Vahid, K. Downey, A. Pang, C. Gordon. Impact of Several Low-Effort Cheating-Reduction Methods in a CS1 Class. SIGCSE 2023. Link to paper.
Note: The above analyses were performed within the allowable use of ChatGPT per their terms of use as of January and February 2023. From https://openai.com/terms/:
(c) Restrictions. You may not (i) use the Services in a way that infringes, misappropriates or violates any person’s rights; (ii) reverse assemble, reverse compile, decompile, translate or otherwise attempt to discover the source code or underlying components of models, algorithms, and systems of the Services (except to the extent such restrictions are contrary to applicable law); (iii) use the Services to develop foundation models or other large scale models that compete with OpenAI; (iv) use any method to extract data from the Services, including web scraping, web harvesting, or web data extraction methods, other than as permitted through the API; (v) represent that output from the Services was human-generated when it is not; or (vii) buy, sell, or transfer API keys without our prior consent. You will comply with any rate limits and other requirements in our documentation. You may use Services only in geographies currently supported by OpenAI.